11751 Week3 Digest
This digest contains two components: the concepts I failed to make sense of in class and important sections.
Out-of-Vocabulary (OOV)
- Definition: In plain language, OOV occurs when a word appears in the test lexicon but does not occur appear in the training data. More technically speaking, Out-of-vocabulary (OOV) are terms that are not part of the normal lexicon found in a natural language processing environment.
- How to handle OOV:
<unk>token- Spell check: only works for mis-spelled words. Can’t do new words.
- Subwords: use facebook’s
fasttextlibrary, orsklearn.feature_extraction.textwithanalyzerset tocharorchar_wb. More details. - BPE: more recommended one.
How does it work? solutionBPE ensures that the most common words are represented in the vocabulary as a single token while the rare words are broken down into two or more subword tokens and this is in agreement with what a subword-based tokenization algorithm does.
Another thing about BPE is that its granularity is somewhere between words (too large, $|\mathcal{V}|$ can be 100k) and characters (too few, only 26). BPE’s vocab size is a good middle point, you can change the vocab size, and it will generate the lexicon with a subword-based tokenization algorithm.
Alignment
Soft Alignment: For each phoneme sequence, which frames belong to which phoneme sequences are probability distributions. Attention-based asr is based on software.

Hard Alignment: No probability distributions. Each frame belongs to only one phoneme sequences.

We can Use Trellis to align phoneme and frames. Below is and example where $N=3$ and $T=5$
Acoustic Model
Unlike the novel attention-based end-to-end ASR, traditional ASR is hmm-based. It helps to understand the basics of ASR. Traditional hmm-based ASR composed of four components, shown as below.
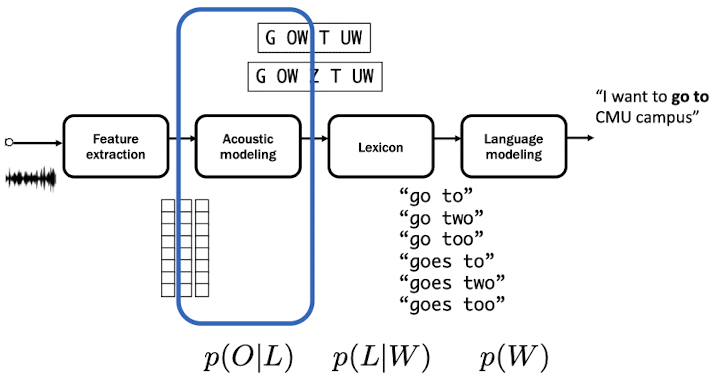
We have talked about the first feature extraction, and will try to factorize the acoustic model. Features and Phonemes in lexicon can be represented in $O$ and $L$ respectively.
$$O=(O_t\in R^D|t=1,\cdots,T)$$
$$L=(l_i\in{/AA/,/AE/,\cdots}|i=1,\cdots,J)$$
Assume that alignment information is given, then acoustic model can be written as
$$\begin{split}
p(O|L)&=p(O_{1:T1},O_{T_1+1:T2},\cdots|l_1,l_2,\cdots)\\
& = p(O_{1:T1}|O_{T_1+1:T2},\cdots,l_1,l_2,\cdots)p(O_{T_1+1:T2},\cdots|l_1, l_2,\cdots)\\
& = p(O_{1:T1}|l_1)p(O_{T_1+1:T2},\cdots|l_1, l_2,\cdots)\\
& \vdots\\
& = p(O_{1:T1}|l_1)p(O_{T_1+1:T2}|l_2)\cdots\\
& = \prod_{i=1}^{J}p(O_{T_{j-1}+1:T_j}|l_j)\\
\end{split}$$
Two rules has been appied:
Feature Extraction
- MFCC: Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In-Between. The best explanation for MFCC and its extraction process.
- Pitch: In speech, the relative highness or lowness of a tone as perceived by the ear, which depends on the number of vibrations per second produced by the vocal cords. Pitch is the main acoustic correlate of tone and intonation.
11751 Week3 Digest