11751 - Week1 Digest
Aug 29 Lecture 1
Grading Policy
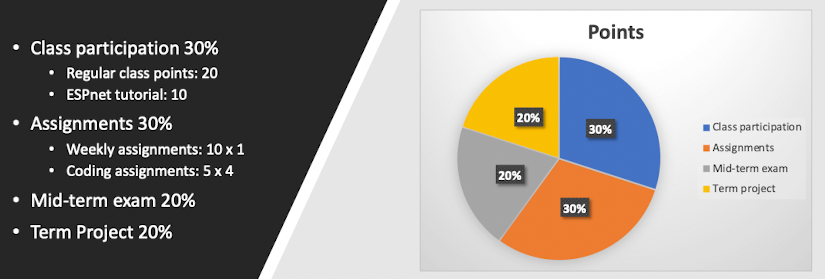
Quizes
Will be quizes during the course, makes up the participation score, deadline is at end of class.
Assignments
There are four assignments in total,
- Coding assignment 1 (Feature extraction): release 9/7, due 9/23
- Coding assignment 2 (HMM): release 9/28, due 10/14
- Coding assignment 3 (N-gram): release 10/12, due 11/4
- Coding assignment 4 (E2E ASR): release 11/2, due 11/18
Aug 31 Lecture 2
Evaluation Metrics of ASR
Sentence Error Rate
Entire sentence (utterance) is correct or not. Either 0 or 1. It is sometimes too strict, we should consider local correctness.
Word Error Rate (WER)
Using Edit Distance. Will introduce Edit Distance in detail later, but for now, in includes insertion error, substitution error, and deletion error. Edit distance is the total count of these three errors.
Character Error Rate (CER)
Motivation: Some languages (Chinese, Japanese) don’t have a concrete definition for word but character.
Still, we use Edit distance to represent the error.
levenshtein Distance (Edit Distance)
Definition: Minimum number of word/character edits (insertions, deletions and substitutions) required to change one sentence into the other.
We first prepare a 2d matrix for hypothesis and reference. Then we insert an empty column and row to avoid errors in the beginning. As shown below,

Each value in the matrix is decided by this algorithm.
$$d[i,j]=min(d[i-1,j]+1, \
d[i, j-1], \
d[i-1, j-1]+localSubstitution(i,j))$$
Be mindful about the substitution case. If our hypothesis has the same token as the reference, then the localSubsitution would be 0, otherwise would be 1. Below, is a mistake I have made.

The rightmost bottom position of the matrix is the edit distance. There can be multiple edit routes to reach the same result.
Software and Corpus Information
Transcriptions
Transcriptions in ASR is like a reference for speeches. There are mainly two styles, Read Speech and Spontaneous Speech. The former is like reading a prompt, the prompt is our transcriptions. The latter needs to transcribe from audio to text. Takes much longer, also higher error rate.
Software for spontaneous speech transcriptions is Audacity, also developed by CMU.
Corpora
Homework
Duration: one week. 4:20pm Sept. 7th.
- all answer in single pdf
11751 - Week1 Digest