11751 - Week2 Digest
[slides]
Premise
We set speech features as $O$ and recognized text as $W$. You will understand better the formulas with this premise in mind.

MAP Decision Rule
Usually,
$$\theta_{MAP}=\underset{\theta}{\operatorname{argmax}}P(\theta|D)$$
Where $\theta$ is a random variable, given the data $D$.
In ASR, the MAP decision theory is similar.
$$\hat{W}=\underset{W\in\mathcal{W}}{\operatorname{argmax}}P(W|O)$$
Where $\hat{W}$ is a sequence of recognized words. The goal is to find the sequence with the highest MAP, given the features $O$.
MAP vs. MLE
MAP is similar to MLE, but have difference. MAP is defined by given data and find the best evaluation of the random variable. MLE is to find the maximum of likelihood given random variables $\theta$. A likelihood function is $P(X|\theta)$. A MLE function is defined as
$$\theta_{MLE}=\underset{\theta}{\operatorname{argmax}}P(X|\theta) \
=\underset{\theta}{\operatorname{argmax}}\prod_iP(x_i|\theta)
$$
A simple example of MLE is when we try to fit a gaussian on some data. We would automatically calculate the mean and variance for the dataset, and use its derivative with respect to the mean and variance, then maximize the likelihood.
Notations
A reminder for using different forms of characters in latex. They hold different meanings.

Be mindful to specify domain when defining vectors and matrix.
- D-dimensional vector: $\mathbf{o}\in\mathbb{R}^D $
- ($D\times D$)-dimensional matrix: $\mathbf{o}\in\mathbb{R}^{D\times D} $
- Sequence representation: (recommended format as follow)
$$O=(\mathbf{O}_t\in\mathbb{R}^D|t=1,\cdots,T)$$
Probilistic Rules
Three Basic Rules
There are three rules of most importance in ASR. Most, if not all formulas can be derived from these three rules.
- Product Rule:
$$p(x,y)=p(x|y)p(y) $$ - Sum rule:
$$p(y)=\sum_xp(x,y) $$ - Conditional Independency Assumption:
$$p(x,y|z)=p(y,x|z)=p(x|z)p(y|z) $$
$$p(x|y,z)=p(x|z) $$
Other Rules
- Bayes Rule:
$$p(x|y)=\frac{p(y|x)p(x)}{p(y)}=\frac{p(y|x)p(x)}{\sum_{x_i}p(y,x_i)}=\frac{p(y|x)p(x)}{\sum_xp(y|x)p(x)} $$
Bayes Rule used Product Rule and Sum Rule. - Probability Chain Rule:
Will add later. Also a problem in homework.
- Viterbi approximation: often used to avoid computation of $\sum_z$
$$p(x|y)=\sum_xp(x,y|z)\approx\underset{z}{\operatorname{max}}p(x,y|z) $$
Extensive knowledge
Connectionist Temporal Classification (CTC) Algorithm
- Clear explanation about motivation, definition and formulas, refer here:
CTC ALGORITHM EXPLAINED PART 1:TRAINING THE NETWORK(CTC算法详解之训练篇) - Clear explanation about CTC Loss, check this out:
详解CTC
If in one sentence should I explain CTC for future review, CTC is an algorithm that can align audio with the texts, so that manual effort can be saved, and transcriptions can be massively labeled. CTC is the foundation for many-to-many generations.
(RNN-)Transducer
For more information about CTC and transducer, CTC-Loss and RNN-TLoss, refer to this:
十二、真正的End2End模型——Transducer
Phoneme
Components
Phoneme is the unit of sound. Speech does not directly transform into text in ASR. Speech cracks into form of a sequence of phonemes, then through some steps they become organized text. Phoneme can be denoted as $L$, where
$$L=(l_i\in{/AA/,/AE/,\cdots}|i=1,\cdots,J) $$ is a phonemes seqence.
With this denotion, we can crack $MAP$ in ASR in more details.
$$
\hat{W}=\underset{W\in\mathcal{W}}{\operatorname{argmax}}P(W|O) \
\overset{\text{Sum Rule}}{===}\underset{W\in\mathcal{W}}{\operatorname{argmax}}\sum_Lp(W,L|O) \
\overset{\text{Product Rule}}{===}\underset{W\in\mathcal{W}}{\operatorname{argmax}}\sum_L\frac{p(O|W,L)p(L|W)p(W)}{p(O)} \
$$
$$
\overset{\text{Independent RV}}{===}\underset{W\in\mathcal{W}}{\operatorname{argmax}}\sum_Lp(O|W,L)p(L|W)p(W) \
\overset{\text{C.I.A}}{===}\underset{W\in\mathcal{W}}{\operatorname{argmax}}\sum_Lp(O|L)p(L|W)p(W) \
$$
C.I.A stands for Conditional Independence Assumption.
In speech recognition, $p(O|L)p(L|W)p(W)$ have special meanings.
Extensive Explanation
What is a Lexicon?
A good explanation from Quora,A lexicon in linguistics is the entire inventory or set of a language’s lexemes. A lexeme is the smallest unit of a language that bears some meaning.
What is N-gram LM?
Will be more intuitive with examples.
e.g: Walden Pond’s water is so transparent that the bottom can easily be discerned at the depth of 25 or 30 feet
bigram: $p(the|that)$ represents the probability of next word being the given the previous one is that, which will be together forming a bigram phrase.
See more details in N-gram Language Models - Stanford University
Acoustic Features
The motivation for feature extraction is to make our data more infomative, more pattern-aware.
There are mainly three kinds of acoustic features: Mel-frequency Cepstrum Coefficient (MFCC), Perceptual Linear Prediction (PLP) and Constant-Q Cepstrum Coefficient (CQCC).
Here is a flow chart of the extraction steps for each feature.
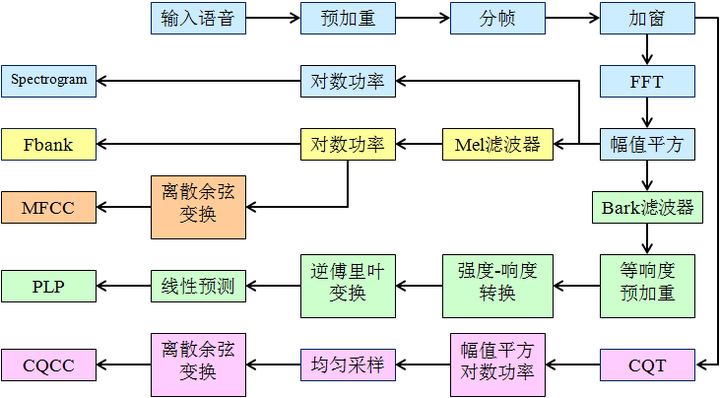
While the most common acoustic feature is MFCC, PLP is proved to be more robust in ASR. Shennong has a tutorial on extracting plp features, the most detailed I could find for python.
Speech Recognition Pipeline
Pipeline

- Acoustic Model: $p(O|L)$. Speech features to phoneme.
- Lexicon: forming word sequence from phoneme sequence.
- Language Model: From word to text. Provides probability for word.

Extensive Questions
- Any pretrained model for speech, analogous to BERT in NLP?
Hmm, I just realized there needs not to be a pretrained language model for speech. After all the input of language model is words not audio pieces.
Here is a collection of the most common language models.
Phoneme
- Definition: one of the units that distinguish one word from another in a particular language. Most popular interface/standard of phoneme: ARPAbet. One can refer to the cmu pronouncing dictionary which is based on the ARPAbet.
11751 - Week2 Digest